
An End-to-End AI Developer Platform
Build, train, and deploy AI models that scale with traffic. No code changes needed.
An End-to-End AI Developer Platform
Build, train, and deploy AI models that scale with traffic. No code changes needed.
An End-to-End AI Developer Platform
Build, train, and deploy AI models that scale with traffic. No code changes needed.
An End-to-End AI Developer Platform
Build, train, and deploy AI models that scale with traffic. No code changes needed.
Trusted By
Trusted By


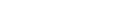


An end-to-end developer platform
From Development to Deployment
From Development to Deployment

>
1
2
3
4
5
6
7
8
9
10
resources:
accelerators: ”A100:8”
workdir: ~/my_project
setup: |
pip install -r requirements.txt
run: |
python train.py --ngpus 8
komo job launch ~/project/train.yaml
Jobs
Launch training jobs with one simple YAML file, and easily scale to multiple nodes for distributed jobs.
Once your job completes, the cloud instances will automatically be terminated. Never pay for idle instances ever again.

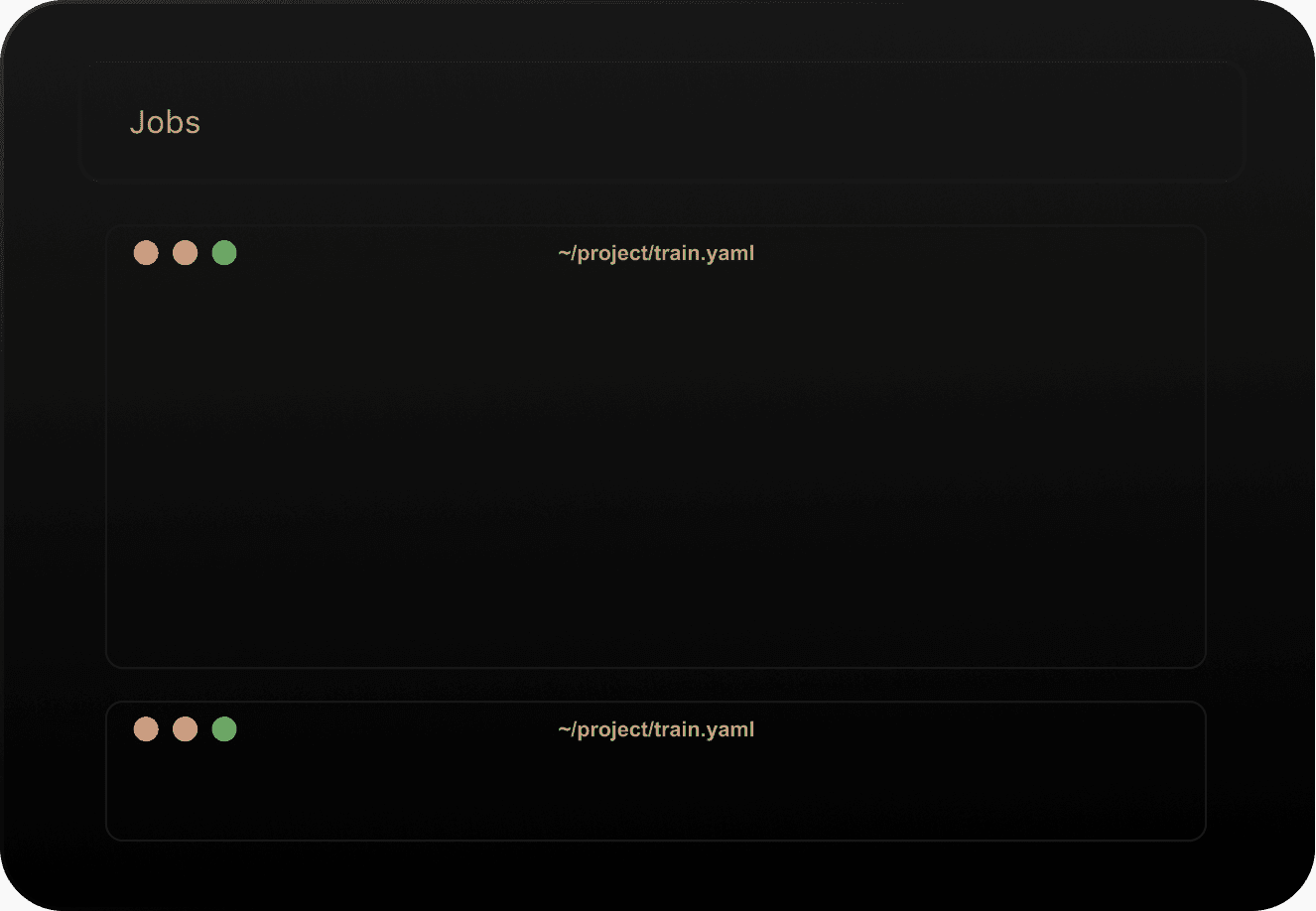
Dev Enviroments
Provision a cloud GPU machine with your environment, code, and SSH keys ready to go.
Connect to it through SSH, Jupyter notebook, or your favorite IDE.
komo job launch ~/project/train.yaml
resources:
accelerators: ”A100:8”
workdir: ~/my_project
setup: |
pip install -r requirements.txt
run: |
python train.py --ngpus 8
1
2
3
4
5
6
7
8
9
10
>
Jobs
Launch training jobs with one simple YAML file, and easily scale to multiple nodes for distributed jobs.
Once your jobs completes, the cloud instances will automatically be terminated. Never pay for idle instances ever again.
>
1
2
3
4
5
6
7
8
9
10
resources:
accelerators: ”A100:8”
workdir: ~/my_project
setup: |
pip install -r requirements.txt
run: |
python train.py --ngpus 8
komo job launch ~/project/train.yaml
Jobs
Launch training jobs with one simple YAML file, and easily scale to multiple nodes for distributed jobs.
Once your job completes, the cloud instances will automatically be terminated. Never pay for idle instances ever again.





Seemless Intergration
Multi-Cloud Execution
Bring your own cloud account or cluster, and seamlessly overflow from your cloud to ours.
Seemless Intergration
Multi-Cloud Execution
Bring your own cloud account or cluster, and seamlessly overflow from your cloud to ours.
Seemless Intergration
Multi-Cloud Execution
Bring your own cloud account or cluster, and seamlessly overflow from your cloud to ours.
A radically better developer experience
The Future of AI Cloud Computing
The Future of AI Cloud Computing

YAML is all you need
Launch tasks on cloud GPUs with one YAML file. No code changes needed.
YAML is all you need
Launch tasks on cloud GPUs with one YAML file. No code changes needed.
Pricing
A100s starting at $1.55/hr and H100s starting at $2.99/hr

LLM Chat
Serve LLMs and chat with them right in the dashboard
08/28/2024 9:24:30: Epoch 2/100: Loss = 1.1722
08/28/2024 9:29:12: Epoch 3/100: Loss = 1.2912
08/28/2024 9:36:39: Epoch 4/100: Loss = 1.1922
08/28/2024 9:19:53: Epoch 1/100: Loss = 1.3824
08/28/2024 9:24:30: Epoch 2/100: Loss = 1.1722
08/28/2024 9:29:12: Epoch 3/100: Loss = 1.2912
08/28/2024 9:36:39: Epoch 4/100: Loss = 1.1922
08/28/2024 9:19:53: Epoch 1/100: Loss = 1.3824
Log Streaming
Stream the logs from your tasks in real-time from the dashbaord

Distributed Training
Easily deploy multi-node training jobs and model services
Coming Soon
Coming Soon
GPU Fractioning
Rent a fraction of an A100/H100 for unbeatable price performance

Serve LLMs and chat with them right in the dashboard
LLM Chat

YAML is all you need
Launch tasks on cloud GPUs with one simple YAML file. No code changes needed.

Pricing
A100s starting at $1.55/hr
H100s starting at $2.99/hr
Coming Soon
Coming Soon
GPU Fractioning
Rent a fraction of an A100/H100 for unbeatable price performance
Distributed Training
Easily deploy multi-node training jobs and model services

Log Streaming
Stream the logs from your tasks in real-time from the dashbaord
08/28/2024 9:24:30: Epoch 2/100: Loss = 1.1722
08/28/2024 9:29:12: Epoch 3/100: Loss = 1.2912
08/28/2024 9:36:39: Epoch 4/100: Loss = 1.1922
08/28/2024 9:19:53: Epoch 1/100: Loss = 1.3824
YAML is all you need
Launch tasks on cloud GPUs with one YAML file. No code changes needed.
YAML is all you need
Launch tasks on cloud GPUs with one YAML file. No code changes needed.
Distributed Training
Easily deploy multi-node training jobs and model services
Distributed Training
Easily deploy multi-node training jobs and model services
Log Streaming
Stream the logs from your tasks in real-time from the dashboard
08/28/2024 9:24:30: Epoch 2/100: Loss = 1.1722
08/28/2024 9:29:12: Epoch 3/100: Loss = 1.2912
08/28/2024 9:36:39: Epoch 4/100: Loss = 1.1922
08/28/2024 9:19:53: Epoch 1/100: Loss = 1.3824
Log Streaming
Stream the logs from your tasks in real-time from the dashboard
08/28/2024 9:24:30: Epoch 2/100: Loss = 1.1722
08/28/2024 9:29:12: Epoch 3/100: Loss = 1.2912
08/28/2024 9:36:39: Epoch 4/100: Loss = 1.1922
08/28/2024 9:19:53: Epoch 1/100: Loss = 1.3824
Pricing
Reserve A100s for $1.55/hr and
H100s for $2.99/hr
Pricing
Reserve A100s for $1.55/hr and
H100s for $2.99/hr
LLM Chat
Serve LLMs and chat with them right in the dashboard
LLM Chat
Serve LLMs and chat with them right in the dashboard
GPU Fractioning
Rent a fraction of an A100/H100 for unbeatable price performance
Coming Soon
GPU Fractioning
Rent a fraction of an A100/H100 for unbeatable price performance
Coming Soon
What our users have to say
Nothing but the best
Nothing but the best
Komodo has one of the best developer experiences I have seen out there. It's 🔥

Pierre Martin
Gavel
As a startup, managing compute was a constant headache—searching for discounts and juggling multiple cloud providers to get a better price. With Komodo, I run a single command and get the resources I need in minutes, without any worries.

Raphael Kalandadze
AI Lab
Before Komodo, I would not have had an A100 running llama 3.1 unless I sank in hours of labor just playing with the settings on different cloud providers. Now, it takes me 10 minutes and 1 command to put up any service I need on their platform. Try it out, you won't want to go back to the way you did ML hosting before.

Aleksandre Lomadze-Gabiani
STORI AI
With Komodo, it took all of five minutes to self-host a model through an endpoint URL. The services feature makes it quick and painless.

Waleed Atallah
A2 Labs
Komodo has been a game-changer for our AI development workflow. It’s the ideal platform for any AI-driven business looking for a seamless, scalable solution

Levan Lashauri
Data Analysis Laboratory
Really impressed by Komodo, it makes developing and deploying LLMs so much easier. Highly recommend to anybody sick of dealing with cloud infrastructure.

Ana Robakidze
Theneo
Komodo has one of the best developer experiences I have seen out there. It's 🔥
Pierre Martin
Gavel
As a startup, managing compute was a constant headache—searching for discounts and juggling multiple cloud providers to get a better price. With Komodo, I run a single command and get the resources I need in minutes, without any worries.
Raphael Kalandadze
AI Lab
Before Komodo, I would not have had an A100 running llama 3.1 unless I sank in hours of labor just playing with the settings on different cloud providers. Now, it takes me 10 minutes and 1 command to put up any service I need on their platform. Try it out, you won't want to go back to the way you did ML hosting before.
Aleksandre Lomadze-Gabiani
STORI AI
With Komodo, it took all of five minutes to self-host a model through an endpoint URL. The services feature makes it quick and painless.
Waleed Atallah
A2 Labs
Komodo has been a game-changer for our AI development workflow. It’s the ideal platform for any AI-driven business looking for a seamless, scalable solution
Levan Lashauri
Data Analysis Laboratory
Really impressed by Komodo, it makes developing and deploying LLMs so much easier. Highly recommend to anybody sick of dealing with cloud infrastructure.
Ana Robakidze
Theneo
Komodo has one of the best developer experiences I have seen out there. It's 🔥
Pierre Martin
Gavel
As a startup, managing compute was a constant headache—searching for discounts and juggling multiple cloud providers to get a better price. With Komodo, I run a single command and get the resources I need in minutes, without any worries.
Raphael Kalandadze
AI Lab
Before Komodo, I would not have had an A100 running llama 3.1 unless I sank in hours of labor just playing with the settings on different cloud providers. Now, it takes me 10 minutes and 1 command to put up any service I need on their platform. Try it out, you won't want to go back to the way you did ML hosting before.
Aleksandre Lomadze-Gabiani
STORI AI
With Komodo, it took all of five minutes to self-host a model through an endpoint URL. The services feature makes it quick and painless.
Waleed Atallah
A2 Labs
Komodo has been a game-changer for our AI development workflow. It’s the ideal platform for any AI-driven business looking for a seamless, scalable solution
Levan Lashauri
Data Analysis Laboratory
Really impressed by Komodo, it makes developing and deploying LLMs so much easier. Highly recommend to anybody sick of dealing with cloud infrastructure.
Ana Robakidze
Theneo
Komodo has one of the best developer experiences I have seen out there. It's 🔥
Pierre Martin
Gavel
As a startup, managing compute was a constant headache—searching for discounts and juggling multiple cloud providers to get a better price. With Komodo, I run a single command and get the resources I need in minutes, without any worries.
Raphael Kalandadze
AI Lab
Before Komodo, I would not have had an A100 running llama 3.1 unless I sank in hours of labor just playing with the settings on different cloud providers. Now, it takes me 10 minutes and 1 command to put up any service I need on their platform. Try it out, you won't want to go back to the way you did ML hosting before.
Aleksandre Lomadze-Gabiani
STORI AI
With Komodo, it took all of five minutes to self-host a model through an endpoint URL. The services feature makes it quick and painless.
Waleed Atallah
A2 Labs
Komodo has been a game-changer for our AI development workflow. It’s the ideal platform for any AI-driven business looking for a seamless, scalable solution
Levan Lashauri
Data Analysis Laboratory
Really impressed by Komodo, it makes developing and deploying LLMs so much easier. Highly recommend to anybody sick of dealing with cloud infrastructure.
Ana Robakidze
Theneo
Questions
Keep in touch
FAQ
FAQ

Can I reserve large GPU clusters in advance?
Can I reserve large GPU clusters in advance?
Can I reserve large GPU clusters in advance?
Can I reserve large GPU clusters in advance?
Can I use my existing cloud credits?
Can I use my existing cloud credits?
Can I use my existing cloud credits?
Can I use my existing cloud credits?
Can I connect multiple cloud accounts?
Can I connect multiple cloud accounts?
Can I connect multiple cloud accounts?
Can I connect multiple cloud accounts?
Can I connect multiple cloud accounts?
What do I need to get my project up and running on Komodo?
What do I need to get my project up and running on Komodo?
What do I need to get my project up and running on Komodo?
What do I need to get my project up and running on Komodo?
What type of environment will I have access to—bare metal, virtual machine, or Docker container?
What type of environment will I have access to—bare metal, virtual machine, or Docker container?
What type of environment will I have access to—bare metal, virtual machine, or Docker container?
What type of environment will I have access to—bare metal, virtual machine, or Docker container?